序
這是一本使用Python從零開始指導讀者的網路爬蟲入門書籍,全書以約404個程式實例,完整解說大數據擷取、清洗、儲存與分析相關知識,若是和第一版做比較,這本書增加下列內容:
1:全書增加約50個程式實例
2:網路趨勢與網路關鍵字查詢
3:國際金融資料查詢
4:YouBike
5:博客來圖書排行榜
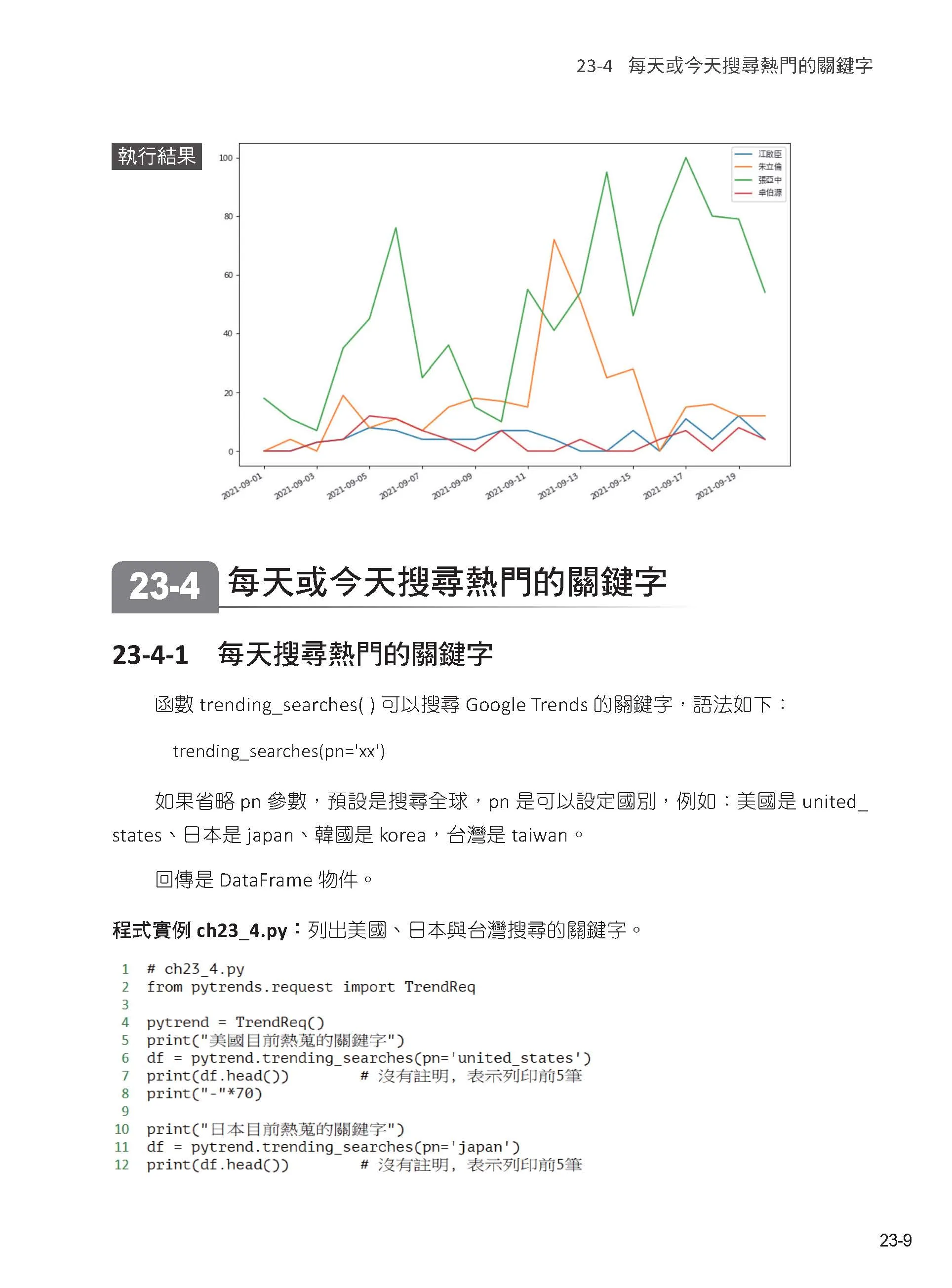
6:租房網站
7:中央氣象局
8:生活應用
在Internet時代,所有數據皆在網路呈現,從網路獲得資訊已經成為我們日常生活的一部份。然而如何從網路上獲得隱性的數據資訊,更進一步做將此數據資訊做擷取、清洗、儲存與分析的有效應用,已經是資訊科學非常重要的領域,目前國內作者這方面著作不多,同時內容單薄,這也是筆者撰寫本書的動力。本書保持筆者一貫特色,實例豐富,容易學習,有系統的一步一步引導讀者深入不同網站主題,進行探索,下列是本書有關網路爬蟲知識的主要內容。
■ 認識搜尋引擎與網路爬蟲
■ 認識約定成俗的協議robots.txt
■ 從零開始解析HTML網頁
■ 認識與使用Chrome開發人員環境解析網頁
■ 認識Python內建urllib、urllib2模組,同時介紹好用的requests模組
■ 說明lxml模組
■ Selenium模組
■ XPath方法解說
■ css定位網頁元素
■ Cookie觀念
■ 自動填寫表單
■ 使用IP代理服務與實作
■ 偵測IP
■ 更進一步解說更新的模組Requests-HTML
■ 認識適用大型爬蟲框架的Scrapy模組
在書籍內容,筆者設計爬蟲程式探索下列相關網站。
■ 國際與國內股市資訊
■ 基金資訊
■ 股市數據
■ 人力銀行
■ 維基網站
■ 主流媒體網站
■ 政府開放數據網站
■ YouBike服務網站
■ PTT網站
■ 電影網站
■ 星座網站
■ 小說網站
■ 博客來網站
■ 中央氣象局
■ 露天拍賣網站
■ httpbin網站
■ python.org網站
■ github.com網站
■ ipstack.com網站API實作
■ Google API實作
■ Facebook API實作
探索網站成功後,筆者也說明下列如何下載或儲存不同資料格式的數據。
■ CSV檔案格式
■ JSON檔案格式
■ XML、Pickle
■ Excel
■ SQLite
在設計爬蟲階段我們可能會碰上一些技術問題,筆者也以實例解決下列相關問題。
■ URL編碼與中文網址觀念
■ 將中文儲存在JSON格式檔案
■ 亂碼處理
■ 簡體中文在繁體中文Windows環境資料下載與儲存
■ 解析Ajax動態加載網頁,獲得更多頁次資料
■ 使用Chromium瀏覽器協助Ajax動態加載
註:讀者需了解網路爬蟲是針對特定網站擷取特定資料,本書所有程式雖經測試,在撰寫當下是正確,筆者同時列出執行結果。但是,如果網站結構改變,可能造成程式失效。
寫過許多的電腦書著作,本書沿襲筆者著作的特色,程式實例豐富,相信讀者只要遵循本書內容必定可以在最短時間精通Python網路爬蟲設計,編著本書雖力求完美,但是學經歷不足,謬誤難免,尚祈讀者不吝指正。
教學資源說明
教學資源有教學投影片,內容超過1500頁。
如果您是學校老師同時使用本書教學,歡迎與本公司聯繫,本公司將提供教學投影片。請老師聯繫時提供任教學校、科系、Email、和手機號碼,以方便深智數位股份有限公司業務單位協助您。
臉書粉絲團
歡迎加入:王者歸來電腦專業圖書系列
歡迎加入:iCoding程式語言讀書會(Python, Java, C, C++, C#, JavaScript, 大數據, 人工智慧等不限),讀者可以不定期獲得本書籍和作者相關訊息。
歡迎加入:穩健精實AI技術手作坊
讀者資源說明
請至本公司網頁deepmind.com.tw下載本書程式實例。